반응형
1. CNN
-
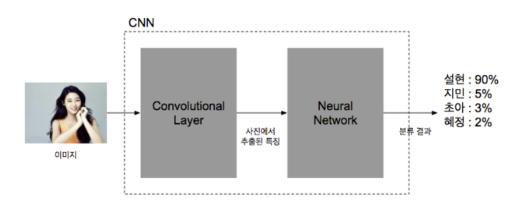
CNN은 전통적인 뉴럴 네트워크 앞에 여러 계층의 convolutional layer를 붙인 모양
-
CNN은 앞의 convolutional layer를 통해서 입력 받은 이미지에 대한 특징을 추출
-
추출된 특징을 기반으로 기존의 뉴럴 네트워크를 이용하여 분류를 함
-
CNN 구성도
-
1-1. Convolutional Layer
-
입력 데이터로부터 특징을 추출함
-
특징을 추출하는 기능을 하는 Filter와 이 필터의 값을 비선형 값으로 바꾸어주는 Activation 함수로 이루어짐
-
Activation 함수로는 ReLu 함수를 주로 사용함

-
1-2. Fully connected Layer
-
Convolution Layer에서 특징이 추출되었으면 이 추출된 특징 값을 기존의 뉴럴 네트워크에 넣어서 분류
2. 시스템 구조
-
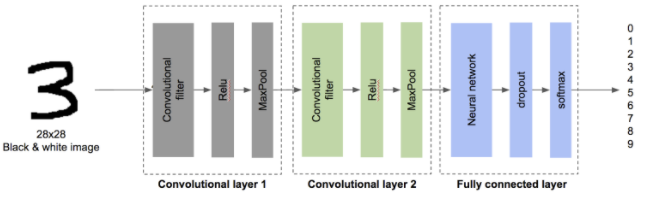
2개의 Convolutional Layer와 Fully connected Layer로 구성됨
-
시스템 구성도
3. 소스코드
-
데이터 로딩 부분
## 데이터 로딩, 각종 변수 초기화
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
# 기존에 생성된 디폴트 그래프 삭제
tf.reset_default_graph()
np.random.seed(20160704)
tf.set_random_seed(20160704)
#load data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
-
Convolutional Layer1
## Convolution Layer1(filter + ReLu + MaxPool)
# 이미지 데이터: 28*28*1(784) / 필터: (5*5*1) 32개
# define First Layer
num_filters1 = 32
x = tf.placeholder(tf.float32, [None, 784])
# 784*무한개인 이미지 데이터 x를, (28*28*1)이미지의 무한개 행렬로 reshape를 이용하여 변경함 [-1, 28, 28, 1]은 28*28*1 행렬을 무한개(-1)로 정의함
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 필터 정의: shape는 (5*5*1) 32개이므로 [5,5,1,32]가 된다
# trucated_normal은 32개의 필터 중 난수를 생성하여 임의의 수를 지정함
W_conv1 = tf.Variable(tf.truncated_normal([5, 5, 1, num_filters1], stddev=0.1))
# 필터 적용: 정의한 필터를 입력 데이터(이미지)에 적용
# strides=[1,1,1,1]은 맨 앞과 맨 뒤는 통상적으로 1을 쓰고, 두번째 1은 가로 스트라이드 값, 세번째 1은 세로 스트라이드 값이 된다.
# padding=SAME 주면 자동으로 패딩을 삽입하여 입력값과 출력값의 크기가 같도록 한다
h_conv1 = tf.nn.conv2d(x_image, W_conv1, strides=[1,1,1,1], padding='SAME')
# Activation function(ReLu) 적용
# b_conv1(y = Wx + b의 bias 값) 정의
b_conv1 = tf.Variable(tf.constant(0.1, shape=[num_filters1]))
# 필터된 결과(h_conv1) + bias 값을 더한 값을 ReLu 함수로 적용
h_conv1_cutoff = tf.nn.relu(h_conv1 + b_conv1)
# Max Pooling
# ksize : 풀링 필터 사이즈로 2*2 사이즈로 묶어서 풀링
# padding은 가로 2칸 세로 2칸씩 움직임
# size가 2*2이고 strides가 2인 맥스 풀링 필터를 적용하게 되면 각각의 행렬의 크기가 반으로 줄어들어 14*14*1 행렬 32개가 리턴된다.
h_pool1 = tf.nn.max_pool(h_conv1_cutoff, ksize=[1,2,2,1], strides=[1,2,2,1], padding="SAME")
-
Convolutional Layer2
## Convolution Layer2(filter + ReLu + MaxPool)
# Convolution Layer1과 같음
# define Second Layer
num_filters2 = 64
# 필터 정의 : 입력되는 값이 32개이므로 32가 들어감, 총 64개의 필터를 적용하기 때문에 마지막 부분은 64가 됨
W_conv2 = tf.Variable(tf.truncated_normal([5, 5 , num_filters1, num_filters2], stddev=0.1))
# 필터 적용
h_conv2 = tf.nn.conv2d(h_pool1, W_conv2, strides=[1,1,1,1], padding="SAME")
# ReLu 적용
# b_conv2 정의
b_conv2 = tf.Variable(tf.constant(0.1, shape=[num_filters2]))
# Relu 함수 적용
h_conv2_cutoff = tf.nn.relu(h_conv2 + b_conv2)
# Max Pooling
# size가 2*2이고 strides가 2인 맥스 풀링 필터를 적용하게 되면 앞에서 줄어들었던 행렬의 크기가 또 반으로 줄어들어 7*7*1 행렬 64개가 리턴된다
h_pool2 = tf.nn.max_pool(h_conv2_cutoff, ksize=[1,2,2,1], strides=[1,2,2,1], padding="SAME")
-
Fully connected Layer
## Fully connected Layer(Nerual network + dropout + softmax) : 두 Convolutional Layer를 통해서 특징을 뽑아냈으면, 이 특징을 가지고 입력된 이미지가 0~9 중 어느 숫자인지 폴리 커넥티드 계층을 통해서 판단함
# define Fully Connected Layer
# 입력된 64개의 7*7 행렬을 1차원 행렬로 변환한다
h_pool2_flat = tf.reshape(h_pool2, [-1,7*7*num_filters2])
# 64*7*7 개의 벡터값을 1024개의 뉴런을 이용하여 학습한다
num_units1 = 7*7*num_filters2
num_units2 = 1024
# w2의 값은 [num_units1,num_units2]로 num_units1은 64*64*7로 입력값의 수를 num_units2는 뉴런 수를 나타낸다
w2 = tf.Variable(tf.truncated_normal([num_units1, num_units2]))
b2 = tf.Variable(tf.constant(0.1, shape=[num_units2]))
# 1024개의 뉴런으로 계산한 후 액티베이션 함수인 ReLu 적용
hidden2 = tf.nn.relu(tf.matmul(h_pool2_flat, w2) + b2)
# 드롭아웃 적용
# 앞의 네트워크에서 전달된 값(hidden2)를 넣고 keep_prob에 연결 비율을 넣는다
# 연결 비율 : 네트워크 전체가 다 연결되어 있으면 1.0, 만약에 50% 드롭아웃 시키면 0.5식으로 입력
keep_prob = tf.placeholder(tf.float32)
hidden2_drop = tf.nn.dropout(hidden2, keep_prob)
# 드롭아웃이 끝난 후에는 결과를 가지고 소프트맥스 함수를 이용하여 10개의 카테고리로 분류(0~9)
w0 = tf.Variable(tf.zeros([num_units2, 10]))
b0 = tf.Variable(tf.zeros([10]))
k = tf.matmul(hidden2_drop, w0) + b0
p = tf.nn.softmax(k)
-
비용함수 정의 및 최적화
## 비용함수 정의
# define loss(cost) function
# t : 학습 데이터 셋에서 읽을 라벨(0~9)
t = tf.placeholder(tf.float32, [None, 10])
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=k, labels=t))
# 비용함수 최적화를 위한 AdamOptimizer를 사용
train_step = tf.train.AdamOptimizer(0.001).minimize(loss)
-
학습
## 학습
# define validation function
# correct_prediction : 학습 결과와 입력된 라벨을 비교하여 맞았는지 틀렸는지 리턴
# argmax: 인자에서 가장 큰 값의 인덱스를 리턴하는데 0~9 배열이 들어가 있어서 가장 큰 값이 학습에 의해 예측된 숫자
# p: 예측에 의한 결과 값, t: 라벨 값
correct_prediction = tf.equal(tf.argmax(p,1), tf.argmax(t,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 학습 세션을 시작하고 변수들 초기화
# prepare session
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
# 배치 학습 시작 및 검증
# start training
# 학습은 10,000번 루프를 돌면서 한번에 50개씩 배치로 데이터를 읽어서 학습을 진행하고, 500번째 마다 중간 학습 결과를 출력한다. 중간 학습 결과에서는 몇 번째 학습인지와 비용 값, 그리고 정확도를 출력해준다
i = 0
for _ in range(10000):
i += 1
# mnist 학습용 데이터 셋에서 50개 단위로 데이터를 읽는다.
batch_xs, batch_ts = mnist.train.next_batch(50)
# batch_xs에는 학습에 사용할 28*28*1 사이즈의 이미지와, 읽은 데이터를 feed_dic을 통해서 입력하고 트레이닝 세션을 시작한다.
# 이 때 마지막 인자에 드롭아웃 계층에서 정의한 변수인 keep_prob를 0.5로 입력함으로써 드롭아웃을 거치지 않으 비율을 정의한다. (50%의 네트워크를 인위적으로 끊도록 함)
sess.run(train_step, feed_dict={x:batch_xs, t:batch_ts, keep_prob:0.5})
if i % 500 == 0:
loss_vals, acc_vals = [], []
# 한번에 검증하지 않고 테스트 데이터를 4등분 한 후, 1/4씩 테스트 데이터를 로딩해서 계산함
# 한꺼번에 많은 데이터를 로딩해서 검증을 할 경우 메모리 문제가 생길 수 있어서 방지하기 위함
for c in range(4):
# /(나누기) 하면
start = (len(mnist.test.labels) // 4) * c
end = (len(mnist.test.labels) // 4) * (c+1)
print(start, end)
loss_val, acc_val = sess.run([loss, accuracy], feed_dict={x:mnist.test.images[start:end], t:mnist.test.labels[start:end], keep_prob:1.0})
loss_vals.append(loss_val)
acc_vals.append(acc_val)
loss_val = np.sum(loss_vals)
acc_val = np.mean(acc_vals)
print('Step: %d, Loss: %f, Accuracy: %f'% (i, loss_val, acc_val))
## 학습결과 저장
saver.save(sess, 'cnn_session')
sess.close()
4. 참고 자료
-
기본 뉴럴 네트워크의 이해
https://tensorflowkorea.gitbooks.io/tensorflow-kr/content/g3doc/tutorials/mnist/beginners/ - 딥러닝 - 컨볼루셔널 네트워크를 이용한 이미지 인식의 개념
https://bcho.tistory.com/1149 - 딥러닝 - CNN을 이용한 숫자 이미지 인식 (1/2) - 학습
https://bcho.tistory.com/1156?category=555440
- 딥러닝 - CNN을 이용한 숫자 이미지 인식 (2/2) - 예측
https://bcho.tistory.com/1157?category=555440
반응형